



Introduction
회사에서 레디스를 단일 노드로 운영하다가 안정성을 높이기 위해 복제라는 개념과 아키텍처에 대해 조사해보았다. 사내 내부 세션을 열어서 조사한 내용을 공유하고 레디스 운영 방식을 개선이 필요한 것을 강조했다. 그리고 그냥 넘어가기에는 공부하고 정리한 내용이 너무 아까워서 이렇게 글로 남기게 됐다.
Redis (REmote DIctionary Server, RDS)
Redis란?
•
인메모리(In-Memory) 기반 key-value 구조의 저장소
◦
데이터를 디스크에 쓰는 구조가 아니라 메모리에서 데이터를 처리하기 때문에 속도가 빠름.
•
String, Lists, Sets, Sorted Sets, Hashes, Bitmaps, HyperLogLogs, Streams 자료 구조를 지원
•
Single Threaded
◦
한 번에 하나의 명령만 처리함.
◦
중간에 처리 시간이 긴 명령어가 들어오면 그 뒤에 명령어들은 모두 앞에 있는 명령어가 처리될 때까지 대기가 필요.
◦
하지만 GET, SET 명령어의 경우 초당 10만 개 이상 처리할 수 있을 만큼 빠름.
•
최적화된 C 코드로 작성되어있음.
복제 및 지속성
•
Redis 는 Master-Slave 아키텍처를 사용하여 비동기식 복제를 지원하기 때문에 데이터가 여러 slave 서버에 복제될 수 있다.
•
이렇게 구성할 경우 주 서버에 장애가 발생하는 경우 요청이 여러 서버로 분산될 수 있으므로 향상된 읽기 성능과 복구 기능을 모두 제공할 수 있다.
•
Redis는 안정성을 제공하기 위해 특정 시점 스냅샷과 데이터가 변경될 때 마다 이를 디스크에 저장하는 Append Only File(AOF) 생성을 모두 지원한다.
◦
스냅샷 : Redis 데이터들을 디스크로 복사
•
스냅샷과 AOF를 통해 장애 발생 시 Redis 데이터를 신속하게 복원할 수 있다.
주요 사용 사례
1. 캐싱
•
다른 데이터베이스 “앞”에 Redis를 배치하여 액세스 지연 시간을 줄이고, 처리량을 늘리며 관계형 또는 NoSQL 데이터베이스의 부담을 줄여줌.
2. 세션 관리
•
Redis는 세션 관리 작업에 매우 적합.
•
세션 키에 대한 적절한 TTL과 함께 빠른 키-값 스토어로 사용하면 간단하게 세션 정보를 관리할 수 있음.
•
주로 게임, 전자 상거래 웹 사이트, 소셜 미디어 플랫픔을 비롯한 온라인 애플리케이션에 필요.
3. 실시간 순위표
•
Sorted Set 자료 구조(데이터 구조)를 사용하면 요소가 목록에 유지되고 점수에 따라 정렬됨.
•
이를 통해 손쉽게 동적 순위표를 생성하여 게임에서 앞서 있는 사람이 누구인지 보여주거나, 좋아요를 가장 많이 받은 메시지를 게시하거나, 선두에 있는 사람이 누구인지 보여주려는 다양한 사례에 사용할 수 있음.
4. 속도 제한
•
이벤트 속도를 측정하고 필요한 경우 제한할 수 있음.
•
Redis 카운터를 사용하여 특정 기간 동안 액세스 요청 수를 세고 한도가 초과되는 경우 조치를 취할 수있음.
•
속도 제한기는 포럼(forum)의 게시물 수를 제한하고, 리소스 사용량을 제한하며, 스패머(spammer)의 영향을 억제하는 데 주로 사용됨.
5. 대기열
•
List 자료 구조를 사용하면 간단한 영구 대기열을 손쉽게 구현할 수 있음.
•
List는 자동 작업 및 차단 기능을 제공하므로 신뢰할 수 있는 메시지 브로커 또는 순환 목록이 필요한 다양한 애플리케이션에 적합함.
6. 채팅 및 메시징
•
Redis에서는 패턴 매칭과 더불어 PUB/SUB 표준을 지원함.
•
따라서 Redis를 사용하여 고성능 채팅방, 실시간 코멘트 스트림 및 서버 상호 통신을 지원할 수 있음.
•
또한 PUB/SUB를 사용하여 게시된 이벤트를 기반으로 작업을 트리거할 수 있음.
레디스 QA
Q1. 레디스는 싱글 스레드인가?

•
Redis는 Single Thread이며 Multiplexing이란 기술을 사용하여 단일 프로세스가 모든 클라이언트 요청을 처리한다.
•
모든 요청이 순차적으로 처리되며, 이는 Node.js의 작동 방식과 매우 유사하다.
•
Redis 2.4부터는 디스크 I/O와 관련된 느린 I/O 작업을 백그라운드에서 수행하기 위해 여러 개의 스레드를 사용하지만 Redis가 단일 스레드를 사용하여 모든 요청을 처리한다는 사실은 바뀌지 않는다.
즉, 단일 스레드의 결과는 요청이 느리게 처리될 때 다른 모든 클라이언트가 이 요청이 처리될 때까지 기다린다. 이런 사유 때문에 Redis를 사용할 때는 명령의 알고리즘 시간복잡도가 문서화되어 있고 잘 확인하여 사용해야 한다.
Q2. Multiplexing?
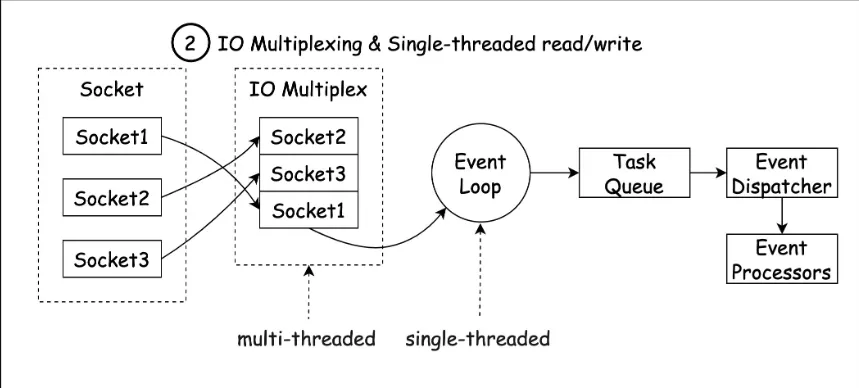
•
하나의 통신 채널을 통해 다량의 데이터를 전송하는 데 사용되는 기술
•
매 요청마다 새로운 프로세스나 쓰레드를 생성하는 게 아니라 요청의 개수와 상관없이 한 개의 프로세스나 스레드를 이용하여 작업을 처리
위 이미지처럼 모든 작업 처리는 단일 콜스택에서 이루어지고 비동기 처리는 Queue를 이용하여 이벤트루프 방식으로 동작한다. 즉, 여러 개의 소켓이 동시에 연결되어 있고, 이들을 관찰하면서 들어오는 작업을 처리하는 것이다.
이와 같이 단일 스레드 이벤트 기반 아키텍처를 사용함으로써 Redis는 스레드 동기화, 컨텍스트 스위칭으로 발생하는 리소스 경합 및 오버헤드, 복잡성을 방지한다.
Q3. Redis Multi Thread?
위 Redis 문서는 I/O 작업 등을 백그라운드에서 처리할 때 여러 개의 쓰레드를 사용한다고 명시되어 있다. 실제로 Redis의 스레드를 조회하면 여러 개가 쓰여지고 있다는 것을 확인할 수 있다.
하지만 하나의 스레드에서만 명령을 처리하고 나머지 스레드들은 Disk를 Flush하거나 파일을 닫기 위해 OS 작업이 되는 것을 메인 스레드에서 처리하게 되면 다른 작업이 느려지기 때문에 해당 작업들은 OS레벨에서 비동기로 처리한다.
즉, Single Thread라는 의미는 클라이언트의 요청인 Redis의 명령어를 처리하는 것에만 유의미하다.
Q4. Multi Thread를 도입한 이유는?
Redis의 성능 병목 형상 중에 하나인 네트워크 IO 작업 때문이다. 프로젝트에서 일부 큰 키-값 쌍을 삭제해야 하는 경우 단시간에 삭제할 수 없으면 단일 스레드의 경우 후속 작업으로 차단된다.
Redis 운영 아키텍처
Stand-Alone
•
말 그대로 Redis를 단일 인스턴스로 동작시키는 방법
•
단일 마스터 노드
Redis Replication
Master와 Replica로 구성되어 Master를 복제하여 수동 장애 조치하는 아키텍처
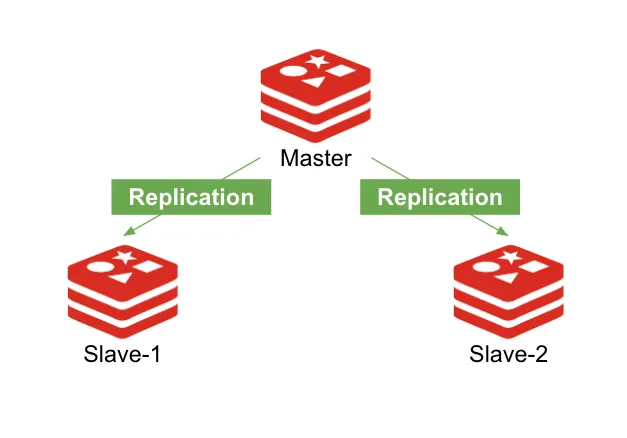
[그림2-1]
복제(Replication)란?
1.
복제(Replication)이란 Redis의 데이터를 거의 실시간으로 다른 Redis 노드에 복사하는 작업이다.
2.
따라서 서비스를 제공하던 첫 번째 Redis 노드가 다운되더라도 데이터를 받은 두 번째 Redis 노드가 서비스를 계속 할 수 있다.
3.
복제 기능이 없을 경우
•
Redis 인스턴스가 사람의 실수 또는 소프트웨어적인 문제로 다운 되었을 때 AOF 기능을 가용하고 있었고 데이터가 많이 쌓여 있었다면, 인스턴스가 시작하는데 몇 분이 걸릴 수도 있다.
•
다운의 원인이 하드웨어적인 문제였다면 서비스를 다시 시작하는 상당한 시간이 소요될 수 있고, 데이터를 복구하지 못할 수도 있다.
4.
Master와 Replica는 물리적으로 다른 서버에 두어야 한다.
특징
•
Replication 아키텍처는 Master와 Replica로 구성된다.
•
Redis는 비동기 복제를 한다.
•
Master는 복제 서버를 여러 개 둘 수 있다.
•
복제 서버는 또 복제 서버를 둘 수 있다.
◦
Master → Replica1 → Replica2 이러한 구성을 의미
•
HA(High Availability, 고가용성) 기능이 없으므로 장애 상황 시 수동으로 복구한다.
◦
장애 상황 시, 스프링에서 새로운 Redis 서버의 연결 정보를 변경 해주어야 함.
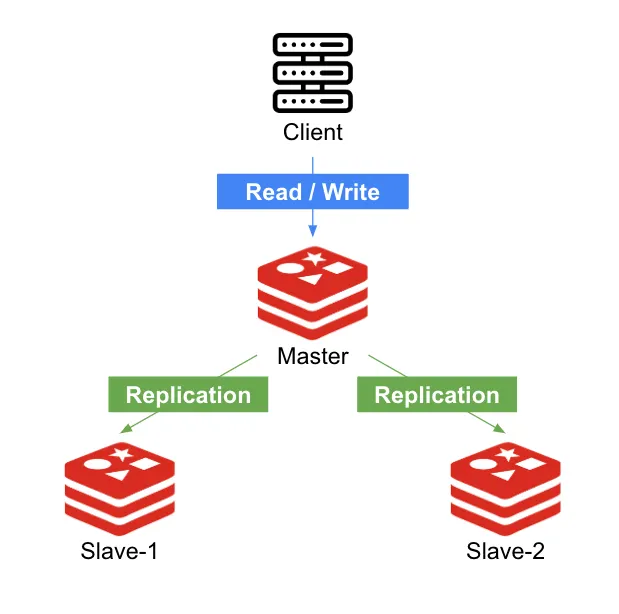
[그림2-2] 마스터가 쓰기/읽기 연산을 처리하는 모습
Master (Leader)
•
Leader 노드 역할
◦
Master 노드는 모든 데이터 변경 작업(쓰기 연산)과 대부분의 읽기 연산을 처리하는 중심적인 역할을 한다.
◦
클라이언트가 Redis에 데이터를 저장하거나 변경할 때, 이 요청은 Master 노드로 전달된다.
•
모든 명령어 처리 (Read / Write)
◦
Master 노드는 [그림2-2]처럼 클라이언트로부터 오는 모든 명령어를 처리한다. 여기에는 데이터 조회(Read)와 데이터 변경(Write) 명령어가 모두 포함된다.
◦
대부분의 Redis 설정에서 읽기 연산 역시 Master 노드에서 처리하는 경우가 많다.
•
Master가 failover 상황 시, Redis는 데이터 손실(data loss)이 발생할 수 밖에 없는 구조
◦
Failover(장애 조치) 상황이란, Master 노드가 장애가 발생하거나 사용할 수 없게 되어, Replica 노드 중 하나가 새로운 Master로 승격되는 상황을 말한다.
◦
이 과정에서 데이터 손실이 발생할 수 있다.
1.
비동기 복제(asynchronous replication): Redis에서 Master와 Replica 간의 데이터 복제는 비동기 방식으로 이루어진다. 이는 Master 노드가 변경된 데이터를 Replica 노드로 전송하지만, 즉각적으로 전송이 완료되지 않을 수 있다는 의미이다.
2.
복제 지연(Replication Lag): Master 노드가 데이터를 변경한 후, 이 변경 내용이 Replica 노드에 완전히 반영되기 전에 Master 노드가 장애가 발생하면, 그 사이에 변경된 데이터는 Replica 노드에 반영하지 못하게 된다. 이로 인해 데이터 손실이 발생할 수 있다.
3.
데이터 일관성 문제: 비동기 복제 방식 때문에 모든 Replica 노드가 Master 노드와 정확히 같은 데이터를 가지고 있지 않을 수 있다. 따라서, Master 노드의 장애 시점에 따라 일부 데이터가 손실 될 수 있다.
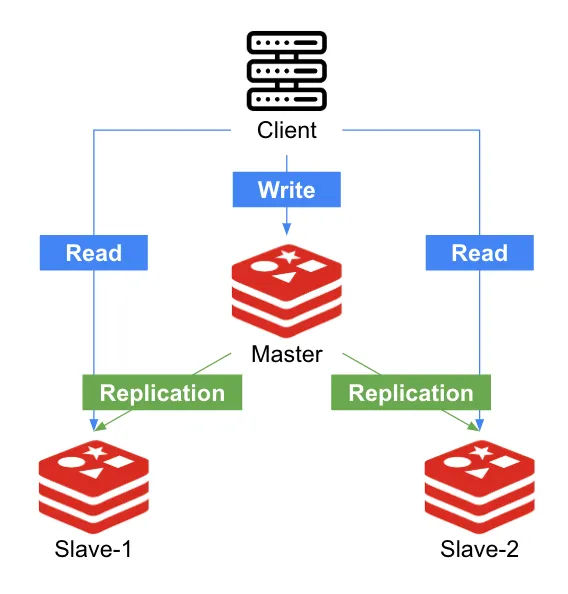
[그림2-3] 마스터에는 쓰기 연산만 처리하고 복제 노드에서 읽기 연산을 처리하는 모습
Replica (Slave / Clone)
•
Master 노드의 복제본
◦
Replica 노드는 Master 노드의 데이터를 복제한 노드이다. Master 노드의 모든 데이터를 동일하게 복사하고 유지하는 역할을 한다.
•
[그림2-3]처럼 Read Only로 데이터를 읽어 갈 순 있음
◦
Replica 노드는 기본적으로 읽기 전용이다. (since Redis v2.6)
◦
redis.conf 파라미터를 통해 설정 가능하다.
▪
replica-read-only : yes or no, default yes
e.g.
◦
Replica 노드에 데이터를 입력 했어도 Master와 Resync되면 입력된 데이터는 사라진다.
•
데이터 일관성(Data Consistency) 문제가 생길 수 있기 때문에 대부분의 경우 Read 역시 Master가 수행함.
◦
데이터 일관성 문제를 방지하기 위해서 대부분의 읽기 연산도 Master 노드에서 수행한다. 만약 읽기 연산을 Replica 노드에서 수
◦
행한다면, 복제 지연(Replication Lag) 때문에 최신 데이터가 아닌 이전 데이터를 읽어올 가능성이 있다.
복제 방식 1. Full synchronization(fsync) : 전체 동기화
Redis v2.8.18 부터는 RDB 파일을 디스크에 만들지 않고 복제하는 기능을 제공
•
복제 순서
1.
Master는 자식 프로세스를 시작해 백그라운드로 RDB 파일에 데이터를 저장.
2.
데이터를 저장하는 동안 Master에 새로 들어온 명령들은 처리 후 복제 버퍼(Buffer)에 저장.
3.
RDB 파일 저장이 완료되면, Master는 파일을 복제 서버에게 전송.
4.
복제 서버는 파일을 받아 디스크에 저장하고, 메모리로 로드.
5.
Master는 복제 버퍼에 저장된 명령을 복제 서버에게 전송.
•
Master가 다운되면 복제 서버는 1초에 한 번씩 Master에 Connection 요청을 보낸다.
•
Master가 복구되면 복제 서버에 복제 순서에 따라 동기화(Sync)한다.
•
복제 서버가 여러 개 일때도 RDB 파일은 하나만 생성한다.
복제 방식 2. Partial synchronization(psync) : 부분 동기화
부분 동기화 기능은 Redis v2.8 부터 제공
•
Master와 복제 서버는 각 서버의 run id와 replication offset을 가지고 있다.
•
Master와 복제 서버 간의 네트워크가 끊어지면 Master는 복제 서버에 전달할 데이터를 backlog-buffer에 저장한다.
•
다시 연결되었을 때, backlog-buffer가 넘치지 않았으면 run id와 offset을 비교해서 그 이후 부터 동기화를 진행한다.
◦
이것을 부분 동기화라고 한다.
•
Backlog-buffer 크기는 repl-backlog-size 파라미터로 설정 가능하다.
e.g.
•
네트워크 단절 시간이 길어져 Master의 backlog-buffer가 넘치면 다시 연결되었을 때 전체 동기화를 한다.
•
Master나 복제 서버 중 한 쪽이 재시작 했을 경우에도 전체 동기화를 한다.
복제 방식 3. Master : 디스크를 사용하지 않는 동기화 (Diskless replication)
•
이 기능은 Redis를 캐시 용도로 사용할 경우 또는 Master가 설치된 서버의 디스크 성능이 좋지 않을 경우 이용할 수 있다.
◦
디스크를 사용하지 않는 것은 Master만 적용된다.
◦
복제 서버는 받은 데이터를 RDB 파일에 저장한다.
◦
Master의 자식 프로세스가 RDB 데이터를 소켓을 통해서 복제 서버에게 직접 쓰는 방식이다.
•
redis.conf(Master) 파라미터를 통해 설정 가능하다.
◦
repl-diskless-sync : no or yes, default no
e.g.
◦
yes로 설정하면 디스크를 사용하지 않고 동기화가 된다.
•
여러 복제 서버에서 요청이 들어올 경우, 기본적을 첫 번째 복제 서버의 소켓에 데이터를 전송하고, 완료되면 다음 복제를 처리한다.
•
몇 개의 복제 서버를 한 번에 처리할 수 있도록 요청을 기다리는 옵션
◦
redis.conf(Master) 파라미터를 통해 설정 가능하다.
▪
repl-diskless-sync-delay : 5
e.g.
▪
첫 번째 요청이 온 후 5초(설정한 값) 동안 다른 복제 서버의 요청을 기다렸다가, 요청이 오면 같이 처리한다.
▪
즉, 5초 안에 3개 복제 서버에 동기화 요청이 왔다면 이는 병렬로 처리할 수 있다.
▪
즉시 처리하도록 설정하려면 0으로 설정한다.
복제 방식 4. Replica : 디스크를 사용하지 않는 동기화 (repl-diskless-load)
Redis v6.0 부터 사용 가능
•
복제 서버에서 디스크를 사용하지 않는 동기화 방식이다.
◦
즉, 복제 서버에 RDB 파일을 생성하지 않는다.
•
redis.conf(Replica) 파라미터를 통해 설정한다.
◦
repl-diskless-load : disable or on-empty-db or swapdb, default disabled
e.g.
•
disabled
◦
diskless를 사용하지 않는다.
•
on-empty-db
◦
복제 서버에 데이터(키)가 없을 경우에 적용, 데이터가 있으면 RDB 파일을 생성해서 복제한다.
•
swapdb
◦
복제 서버에 데이터(키) 여부와 상관없이 diskless로 동작한다.
◦
이 경우 만약의 사태에 대비해서 기존 데이터를 메모리(RAM)에 보존한다.
◦
복제가 성공하면 RAM에 보존한 데이터는 지운다.
◦
복제가 실패하면 RAM에 보존한 데이터로 복구한다.
▪
이 경우 기존 데이터 + 새 데이터 만큼 메모리(RAM)이 필요하므로 충분한 메모리가 있어야 한다.
Redis Sentinel
Sentinel, Master, Replica로 구성되어 자동 장애 조치가 가능한 고가용성 아키텍처
Redis Sentinel은 주기적으로 Redis 서버들을 모니터링하여 Master 서버가 서비스할 수 없는 상태가 되면 다른 Replica 서버를 Master 서버로 변경하여 Redis 서버들을 관리한다.
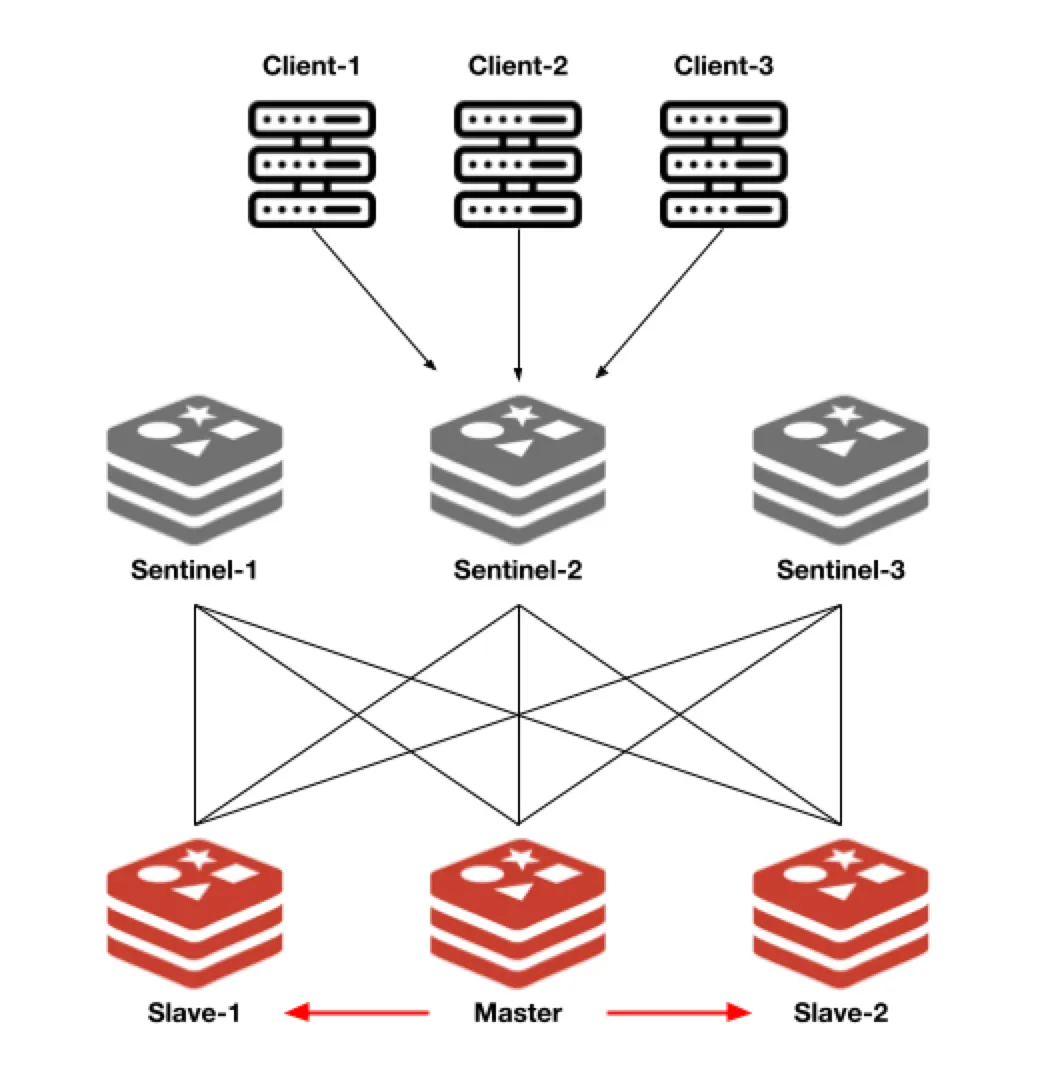
주요 기능
•
모니터링: Redis 노드가 제대로 동작하는지 지속적으로 감시
•
자동 장애 조치(Automatic Failover)
•
알림(Notification): failover 되었을 때 PUB/SUB으로 클라이언트에게 알리거나, Shell script로 이메일이나 SMS를 보낼 수 있다.
특징
•
Sentinel은 1차 복제만 Master 후보에 오를 수 있다. (복제 서버의 복제 서버는 불가능)
◦
1차 복제 서버 중 replica-priority 값이 가장 작은 서버가 마스터로 선정된다. 0으로 설정하면 Master로 승격이 불가능하고 동일한 값이 있을 땐 엔진에서 선택한다.
•
Master가 비정상일 때 자동으로 장애를 조치한다.
•
애플리케이션은 Sentinel과 연결하기 때문에, 장애 상황 발생 시 연결 정보를 변결할 필요가 없다.
◦
장애 조치가 발생하면 Sentinel은 새 주소를 알려준다.
•
Sentinel 노드도 장애 상황이 발생할 수 있기 때문에 안정적인 운영을 위해 반드시 3대 이상의 홀수로 존재해야 한다.
◦
과반 수 이상의 Sentinel의 동의(Quorum based)가 있어야 Failover가 진행한다.
•
각 Sentinel은 서로 물리적으로 영향을 받지 않도록 서로 다른 서버에 설치되는 것이 좋다.
◦
Sentinel을 Redis와 동일한 노드에 구성해도 되고, 별도로 구성해도 된다. 많은 리소스가 필요하므로 Sentinel과 Master 혹은 Replica를 같은 서버에 올려서 사용하기도 한다.
•
Sentinel + Redis 구조의 분산 시스템은 Redis가 비동기 복제를 사용하기 때문에 장애가 발생하는 동안 썼던 내용들이 유지됨을 보장할 수 없다.
•
데이터 사이즈가 커지면 Scale-Up을 해야한다.
동작 방식
•
Sentinel 인스턴스 과반 수 이상이 Master 장애를 감지하면 Slave 중 하나를 Master로 승격시키고 기존의 Master는 Slave로 강등시킨다.
 과반 수 이상으로 결정하는 이유: 어떤 Sentinel이 단순히 네트워크 문제로 Master와 연결되지 않을 수 있는데, 이 때 실제로 Master는 다운되지 않았으나 연결이 끊긴 Sentinel은 Master가 다운되었다고 판단할 수 있기 때문이다.
과반 수 이상으로 결정하는 이유: 어떤 Sentinel이 단순히 네트워크 문제로 Master와 연결되지 않을 수 있는데, 이 때 실제로 Master는 다운되지 않았으나 연결이 끊긴 Sentinel은 Master가 다운되었다고 판단할 수 있기 때문이다.•
Slave가 여러 개 있을 경우 Slave가 새로운 Master로부터 데이터를 받을 수 있도록 재구성한다.
Failover
•
SDOWN: Subjectively down (주관적 다운)
◦
Sentinel에서 주기적으로 Master에게 보내는 PING과 INFO 명령의 응답이 3초(down-after-milliseconds 에서 설정한 값) 동안 응답이 오지 않으면 주관적으로 다운으로 인지한다.
◦
Sentinel 한 대에서 판단한 것으로, 주관적 다운만으로만 장애조치를 진행하지 않는다.
•
ODOWN: Objectively down (객관적 다운)
◦
설정한 Quorum 이상의 Sentinel에서 해당 Master가 다운되었다고 인지하면 객관적 다운으로 인정하고 장애 조치를 진행한다.
Quorum(정족수, 분산 트랜잭션이 얻어야 하는 최소 투표 수): Redis 장애 발생 시, 몇 개의 Sentinel이 특정 Redis의 장애 발생을 감지해야 장애라고 판별하는지를 결정하는 기준 값이다. 보통 Redis의 과반 수 이상으로 설정한다.Failover 주의 사항
•
get-master-addr-by-name
◦
Master, Slave 모두 다운되었을 때 Sentinel에 접속해 Master 서버 정보를 요청하면 다운된 서버 정보를 리턴한다. 따라서 INFO Sentinel 명령으로 마스터의 status를 확인해야 한다.
•
Slave에서 Master로 승격이 안되는 경우
◦
Slave 다운 → Master 다운 → 다운된 Slave가 재시작되면 재시작된 Slave는 Master로 전환되지 않는다. Slave의 redis.conf 에 자신이 복제로 되어 있고, Sentinel도 복제라고 인식하고 있기 때문이다. 해결책은 시작하기 전에 redis.conf에서 slaveof를 삭제하는 것이다.
•
Failover Timeout 만큼 Write 연산 실패
◦
데이터량에 따른 최적의 Failover Timeout 값을 찾고 sentinel.conf 에 적용해야 한다.
Redis Cluster
클러스터에 포함된 노드들이 서로 감시하고 통신하도록 구성하는 아키텍처 (Redis v3.0 부터 제공)
Redis Cluster는 Cluster에 포함된 노드들이 서로 통신하면서 고가용성을 유지한다. 거기에 샤딩 기능까지 기본 기능으로 사용할 수 있다. Cluster 내부에는 Sentinel과 동일하게 Master와 Replica는 짝을 이루어 데이터를 복제한다. Cluster 내부의 모든 노드는 모두 서로 연결되어 있는 Full-mesh 구조로 되어있으며, 가십 프로토콜(gossip protocol)을 사용하여 서로 모니터링 한다.
주요 기능
•
자동 장애 조치(Automatic Failover)
•
샤딩(Sharding) : 데이터를 분산 저장
동작 방식
•
Master 1, 2, 3이 있다면 데이터는 3개 중에 하나에 저장되며, 클라이언트가 데이터 읽기 요청 시 저장된 곳이 아닌 다른 Master에 요청 했다면 저장된 Master 정보를 알려주고 클라이언트는 전달받은 Master 정보에 다시 요청해서 데이터를 받아와야 한다.
◦
이 부분은 Redis Cluster를 지원하는 라이브러리에서 다 해준다.
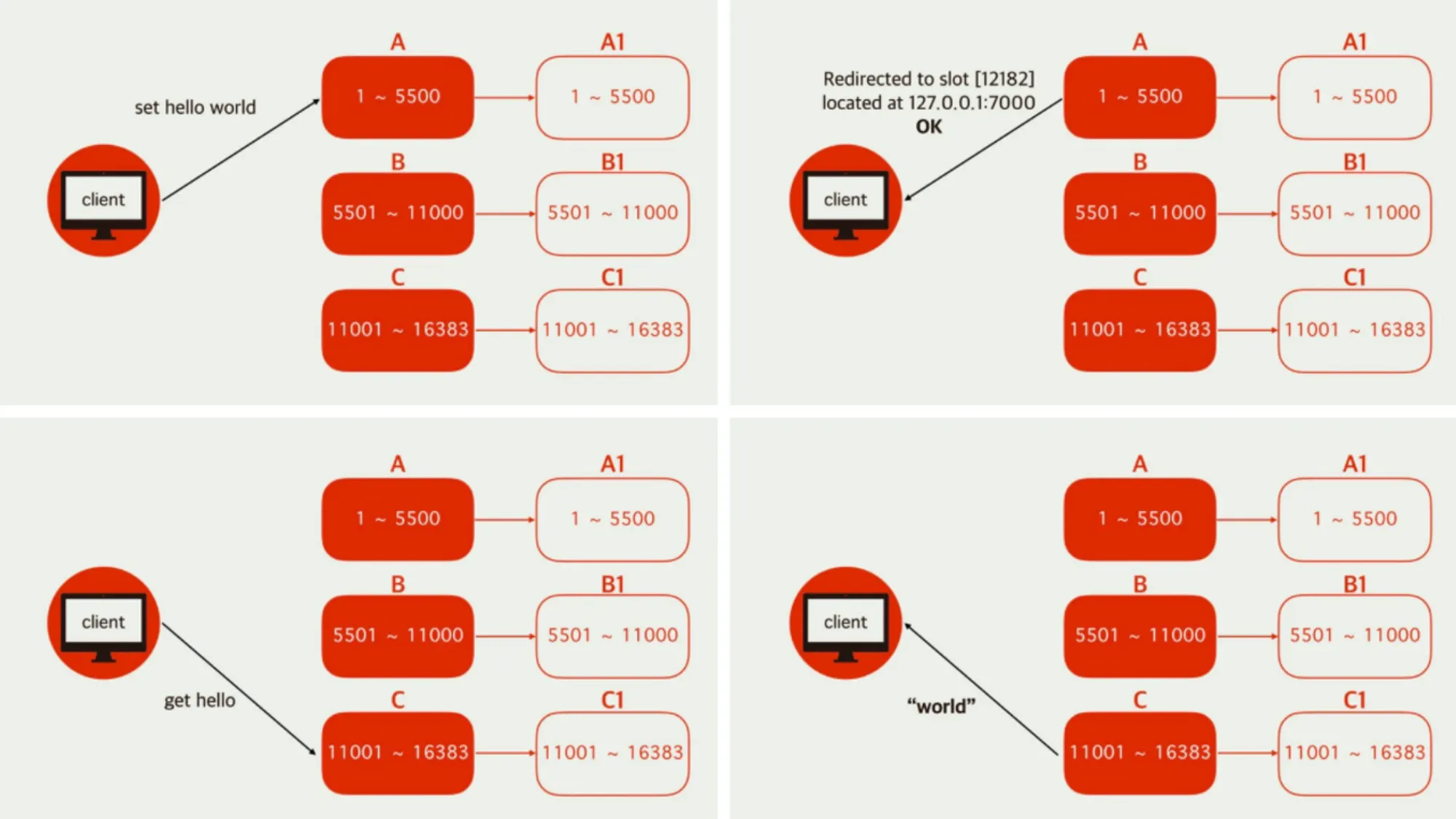
클라이언트 요청 흐름
•
Slave가 죽어서 Replica 노드가 없는 Master가 생길 시, 다른 Master 노드에 여유분이 있다면 해당 노드로 빈자리를 채울 수 있다.
◦
이 부분은 사용자가 개입하지 않고 Redis Cluster가 알아서 해준다.
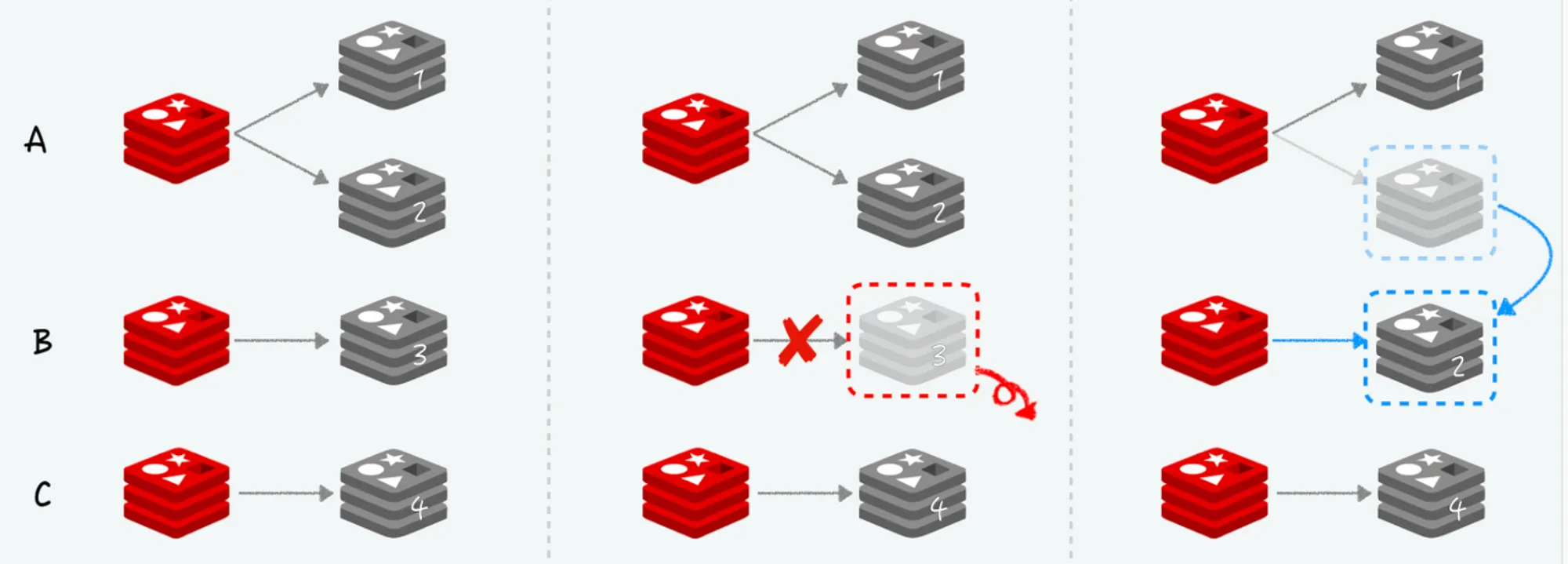
•
해시 슬롯을 이용해 데이터를 샤딩한다.
◦
해시 슬롯(Hash Slot)
▪
CRC-16 해시 함수를 이용해 key를 정수로 변환하고 해당 정수값을 16,385로 모듈 연산한 값을 의미한다.
▪
해시 함수는 CRC16 function을 사용한다.
◦
Cluster는 총 16384개의 해시 슬롯이 있으며 각 Master 노드에 자유롭게 할당 가능하다.
▪
Redis 노드가 3개 일 경우, 1번 노드는 0-5460, 2번 노드는 5461-10922, 3번 노드는 10923-16383 슬롯을 가지게 된다.
▪
슬롯을 노드에 할당하는 것은 Redis Cluster가 한다.
Failover
•
Master가 다운된 경우 Master의 Slave는 gossip Protocol을 통해 Master의 다운 상태를 파악하고, Slave 중에 하나가 Master로 승격된다.
•
단, Failover가 발생하면 Slave가 Master로 승격될 때까지, 문제가 발생한 Master로 할당된 슬롯의 키는 사용할 수 없다. 이는 일시적으로 데이터에 접근이 불가한 상태이다.
◦
하지만 복제는 데이터 삽입시에 바로 실행되므로, 일반적으로 Failover 프로세스는 빠르게 완료된다.
◦
따라서 사용자에게 미비한 영향을 끼친다.
•
다운된 기존 Master가 다시 복구되면 새로운 Master의 Slave로 강등된다.
•
Failover 프로세스
1.
Master 노드의 장애가 감지되면 Failover가 트리거 된다.
2.
Slave 노드 중 하나를 새로운 Master 후보보 선정한다.
3.
다른 Slave 노드들이 과반수가 승인하면 실제로 Master로 승격한다.
4.
클라이언트는 기존 Master에 대한 연결을 해제하고 새로은 Master 주소로 다시 연결한다 (라이브러리에서 지원)
5.
새로운 Master를 기준으로 클러스터 구성을 업데이트한다.
노드 간 통신
Redis Cluster의 각각의 노드는 두 개의 TCP 연결을 사용합니다. 하나는 클라이언트에 연결되는 포트이고 또 하나는 Cluster 내에서 데이터 통신을 위해 사용하는 포트입니다. 두 번째 연결은 클러스터 버스라고 부르는데, 이 클러스터 버스로 사용되는 포트는 10000의 차이가 납니다. 따라서 첫 번째 연결 포트가 6379라면 두 번째 클러스트 버스 포트는 16379입니다. 따라서 Redis Cluster를 구축할 때에는 이 두 개의 TCP 연결이 방화벽에 의해 막혀있는지 꼭 확인해야합니다.
•
클러스터 버스(Cluster-bus)
◦
Redis Cluster 내의 노드들 간의 통신을 위한 전용 네트워크 채널입니다.
◦
클러스터 버스를 통해 노드들은 데이터를 동기화하고, 상태 정보를 교환하며, 클러스터 관리와 관련된 여러 작업을 수행합니다.
◦
클러스터 버스는 가십 프로토콜을 포함하여 여러 통신 메커니즘을 운반하는 역할을 합니다.
•
가십 프로토콜(Gossip Protocol)
◦
Redis 클러스터에서 노드들 간의 상태 정보를 교환하기 위해 사용하는 통신 프로토콜입니다.
◦
가십 프로토콜은 각 노드가 주기적으로 자신과 연결된 다른 노드와 정보를 교환하여, Cluster 전체의 상태를 점진적으로 동기화하는 방식으로 작동합니다.
◦
이 프로토콜은 노드의 추가, 제거, 장애 상태 등의 정보를 효율적으로 전파합니다.
◦
가십 프로토콜은 클러스터 버스를 통해 구현됩니다.
Sentinel과의 차이점
•
가장 큰 차이점은 샤딩을 제공한다는 점이다.
◦
이 때문에 멀티 키 명령(Multikey Operation)이 제한된다.
◦
Master 노드가 여럿 존재할 수 있다
◦
샤딩을 위해 해시 슬롯이 정의 되어야한다.
•
노드 관리를 위한 Sentinel 노드가 별개로 필요하지 않는다.
•
Sentinel은 Sentinel이 노드들을 감시했지만, Cluster에서는 모든 노드가 서로 감시한다.
특징
•
Sentinel보다 더 발전된 형태이다.
•
최소 3개의 Master 노드가 있어야 구성이 가능하다.
•
Sentinel은 Sentinel이 노드들을 감시했지만, Cluster에서는 모든 노드가 서로 감시한다.
•
Multi-Master, Multi-Slave 구조이다.
◦
1000대의 노드까지 확장 가능하다.
◦
모든 데이터는 Master 단위로 샤딩되고 Slave 단위로 복제된다.
◦
Master 마다 최소 하나의 Slave를 두는 것을 추천한다.
◦
Slave가 하나도 없을 때 Master 노드에 장애가 발생하면 해당 데이터 유실이 발생한다.
•
노드를 추가/삭제할 때 운영 중단 없이 Hash Slot을 재구성할 수 있다.
•
키 이동 시에 해당 키에 잠시 락이 걸릴 수 있다.
•
과반수 이상의 노드가 다운되면 Cluster가 깨진다.
•
복제는 비동기 방식으로 이루어지기 때문에 데이터 정합성이 깨질 수 있는데 이때 나중에 Master가 된 노드의 데이터를 기준으로 정합성을 맞춘다.
제한 사항
•
기본적으로 멀티 키 명령(Multikey Operation)을 수행할 수 없다.
◦
e.g. MSET key1 value1 key2 value2, SUNION key1 key2, SORT 이러한 명령은 Cluster에서 사용할 수 없다.
◦
하지만 Hash Tag를 사용하면 사용할 수 있다.
▪
Hash Tag는 키의 일부를 {} 로 감싸는 것이다.
•
e.g. 예를 들어 {user001}.follow와 {user001}.followers는 같은 슬롯에 저장된다.
•
Cluster 모드에서는 DB 0번만 사용할 수 있다.
•
멀티 키 명령에 대해서는 Enterprise 게이트 서버를 사용하면 멀티 키 명령을 사용할 수 있다.
아키텍처 비교표
구분 / 아키텍처 | Stand-Alone | Replication | Sentinel | Cluster |
고가용성 | X | X | | |
복제 | X | | | |
자동 장애 조치 | X | X | | |
샤딩 / Scale-Out | X | X | X | |
아키텍처 선택 기준
•
자동 장애 조치가 필요하고, Scale-out이 필요하다. → Cluster
•
자동 장애 조치가 필요하지만, Scale-out까지는 필요하지 않다. → Sentinel
•
수동 장애 조치여도 괜찮지만 복제 기능은 필요하다. → Replication
•
복제 기능도 필요 없고, Scale-out도 필요하지 않다. → Stand-Alone
“오버 엔지니어링이 되지 않도록 현재 상황에 맞게 적절한 아키텍처를 선택하자”
More posts like this
Search


